Linux并发与竞争
在驱动中有可能存在, 对于公用的资源, 产生的原因, 多任务, 中断, 抢占, 多核
会竞争资源, 就是数据, 需要进行保护, 首先就是全局变量,
常用的处理方法
原子操作
分为原子整形, 原子位操作
就是不能进一步分割的操作, 保证几条代码不会被分开执行, Linux提供了对于整形以及位操作的函数
整形操作API
提供了一个结构体用来进行操作, 定义在include/linux/types.h文件中
typedef struct {
int counter;
} atomic_t;
在定义变量的时候使用这个结构体进行定义
可以在定义的时候进行赋值
atomic_t b=ATOMIC_INIT(0);//定义原子变量b并赋初值为0
在定义的时候不能直接进行赋值
#define ATOMIC_INIT(i) { (i) }
在使用的时候有专门的函数,
| 函数 | 描述 |
|---|---|
ATOMIC_INIT(int i) |
定义原子变量的时候对其初始化。 |
int atomic_read(atomic_t *v) |
读取v的值,并且返回。 |
void atomic_set(atomic_t *v, int i) |
向v写入i值。 |
void atomic_add(int i, atomic_t *v) |
给v加上i值。 |
void atomic_sub(int i, atomic_t *v) |
从v减去i值。 |
void atomic_inc(atomic_t *v) |
给v加1,也就是自增。 |
void atomic_dec(atomic_t *v) |
从v减1,也就是自减 |
int atomic_dec_return(atomic_t *v) |
从v减1,并且返回v的值 |
int atomic_inc_return(atomic_t *v) |
给v加1,并且返回v的值 |
int atomic_sub_and_test(inti, atomic_t *v) |
从v减i,如果结果为0就返回真,否则返回假 |
int atomic_dec_and_test(atomic_t *v) |
从v减1,如果结果为0就返回真,否则返回假 |
int atomic_inc_and_test(atomic_t *v) |
给v加1,如果结果为0就返回真,否则返回假 |
int atomic_add_negative(inti, atomic_t *v) |
给v加i,如果结果为负就返回真,否则返回假 |
typedefstruct{
longlongcounter;
}atomic64_t;
有64位的, 在64位机器使用
原子位操作
不像原子整形变量那样有个atomic_t的数据结构,原子位操作是直接对内存进行操作
| 函数 | 描述 |
|---|---|
void set_bit(intnr, void*p) |
将p地址的第nr位置1。 |
void clear_bit(intnr,void*p) |
将p地址的第nr位清零 |
void change_bit(intnr, void*p) |
将p地址的第nr位进行翻转。 |
int test_bit(intnr,void *p) |
获取p地址的第nr位的值。 |
int test_and_set_bit(intnr, void*p) |
将p地址的第nr位置1,并且返回nr位原来的值。 |
int test_and_clear_bit(intnr, void*p) |
将p地址的第nr位清零,并且返回nr位原来的值。 |
int test_and_change_bit(intnr, void*p) |
将p地址的第nr位翻转,并且返回nr位原来的值。 |
自旋锁
原子操作只对整形进行操作, 或位操作
当一个线程要访问某个共享资源的时候首先要先获取相应的锁,锁只能被一个线程持有,只要此线程不释放持有的锁,那么其他的线程就不能获取此锁
如果自旋锁正在被线程A持有,线程B想要获取自旋锁,那么线程B就会处于忙循环-旋转-等待状态,线程B不会进入休眠状态或者说去做其他的处理
自旋锁的一个缺点:那就等待自旋锁的线程会一直处于自旋状态,这样会浪费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长
可以用在多核的情况下
也是使用一个结构体
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
定义一个结构体, 然后对结构体进行操作
| 函数 | 描述 |
|---|---|
DEFINE_SPINLOCK(spinlock_t lock) |
定义并初始化一个自选变量。 |
int spin_lock_init(spinlock_t *lock) |
初始化自旋锁。 |
void spin_lock(spinlock_t *lock) |
获取指定的自旋锁,也叫做加锁。 |
void spin_unlock(spinlock_t *lock) |
释放指定的自旋锁。 |
int spin_trylock(spinlock_t *lock) |
尝试获取指定的自旋锁,如果没有获取到就返回0 |
int spin_is_locked(spinlock_t *lock) |
检查指定的自旋锁是否被获取,如果没有被获取就返回非0,否则返回0。 |
被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的API函数,否则的话会可能会导致死锁现象的发生, 原因是在进行锁的时候会关闭内核抢占, 如果A进行休眠, B进行申请不成功会等待, 但是A由于不能抢占只能一直休眠
线程和中断之间, 和上面的情况相同
最好的解决方法就是获取锁之前关闭本地中断
| 函数 | 描述 |
|---|---|
void spin_lock_irq(spinlock_t *lock) |
禁止本地中断,并获取自旋锁 |
void spin_unlock_irq(spinlock_t *lock) |
激活本地中断,并释放自旋锁 |
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags) |
保存中断状态,禁止本地中断,并获取自旋锁。 |
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags) |
将中断状态恢复到以前的状态,并且激活本地中断,释放自旋锁。 |
我们是很难确定某个时刻的中断状态, 因此不推荐使用
spin_lock_irq/ spin_unlock_irq, 建议使用spin_lock_irqsave / spin_unlock_irqrestore
flogs用来保存中断的状态
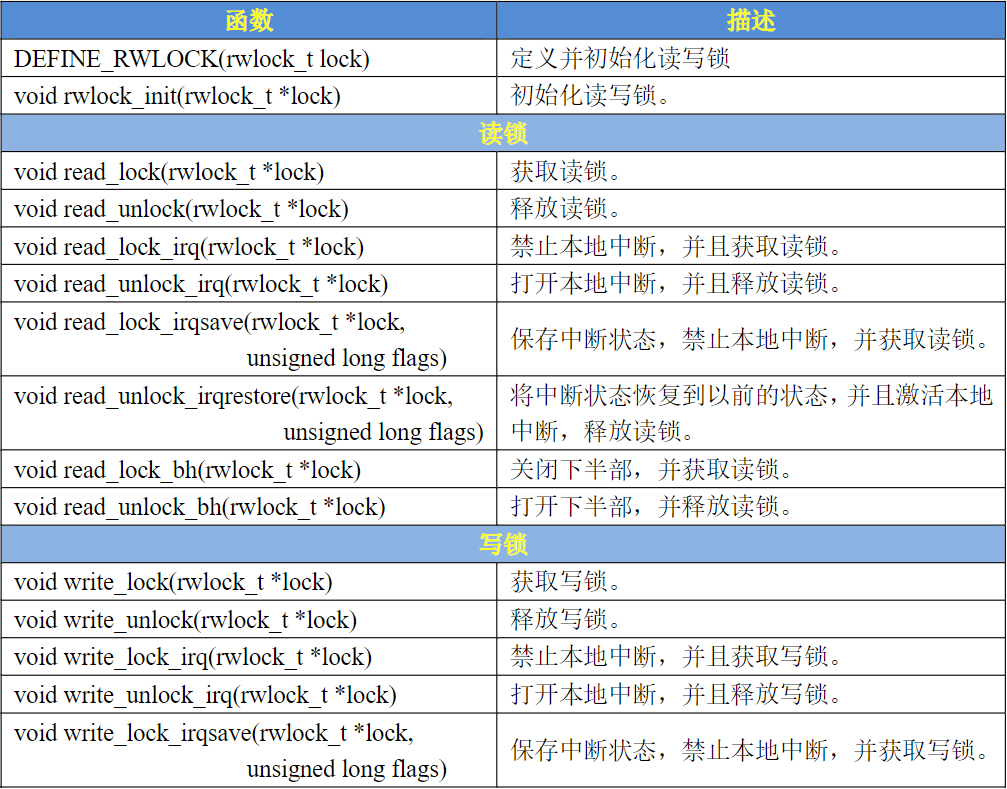
还有其他的锁
- 读写自旋锁
可以有多个进行读, 一个进行写 读写自旋锁为读和写操作提供了不同的锁,一次只能允许一个写操作,也就是只能一个线程持有写锁,而且不能进行读操作。
typedefstruct{
arch_rwlock_t raw_lock;
}rwlock_t;

- 顺序锁
使用顺序锁的话可以允许在写的时候进行读操作,也就是实现同时读写,但是不允许同时进行并发的写操作。如果在读的过程中发生了写操作,最好重新进行读取,保证数据完整性。
保护的资源不能是指针
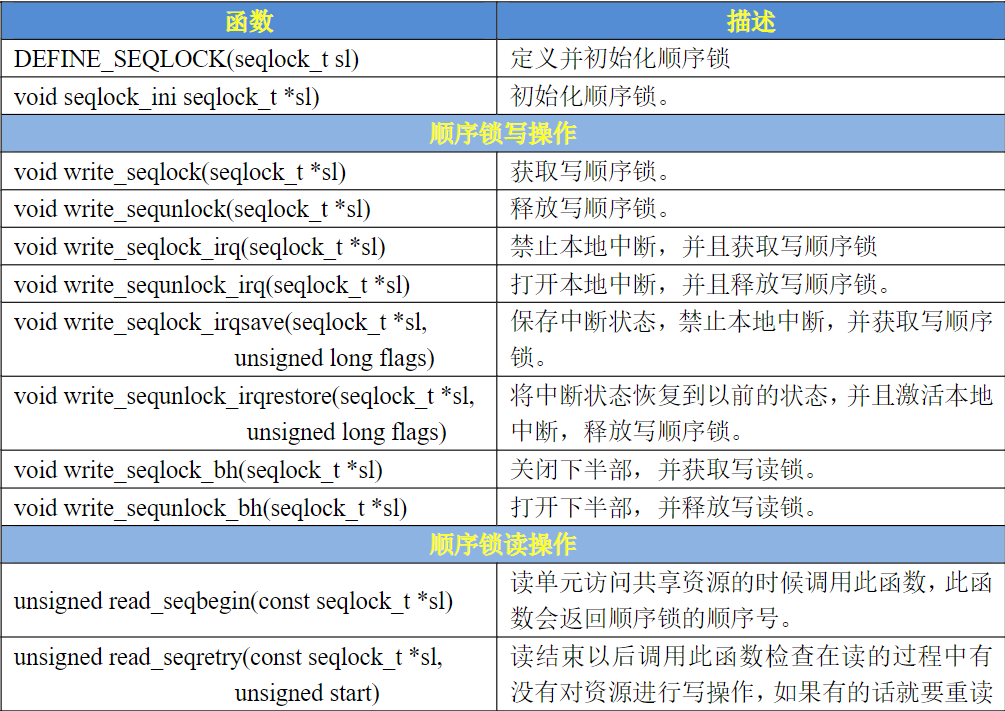
注意事项
在等待的时候会进行自旋, 所以不能持续时间太长
不能调用导致线程休眠的函数
不能递归申请, 否则会自己把自己锁死
为了兼容把所有的当做多核进行编写
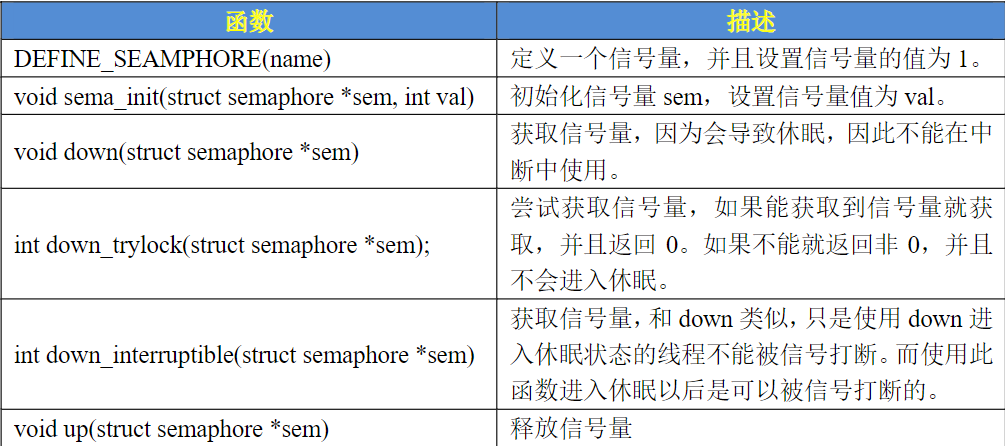
信号量
用来处理长时间, 可以让等待的进程进入休眠状态,
不能用于中断中,因为信号量会引起休眠,中断不能休眠。
如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换线程引起的开销要远大于信号量带来的那点优势。
线程使用自旋锁的时候就不能再使用信号量, 否则有可能进入休眠
信号量有一个信号量值, 可以通过信号量来控制访问共享资源的访问数量,通过信号量控制访问资源的线程数,在初始化的时候将信号量值设置的大于1,那么这个信号量就是计数型信号量,计数型信号量不能用于互斥访问
如果要互斥的访问共享资源那么信号量的值就不能大于1,此时的信号量就是一个二值信号量。
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
structsemaphore sem;/* 定义信号量*/
sema_init(&sem,1);/* 初始化信号量*/
down(&sem);/* 申请信号量*/
/* 临界区*/
up(&sem);/* 释放信号量*/
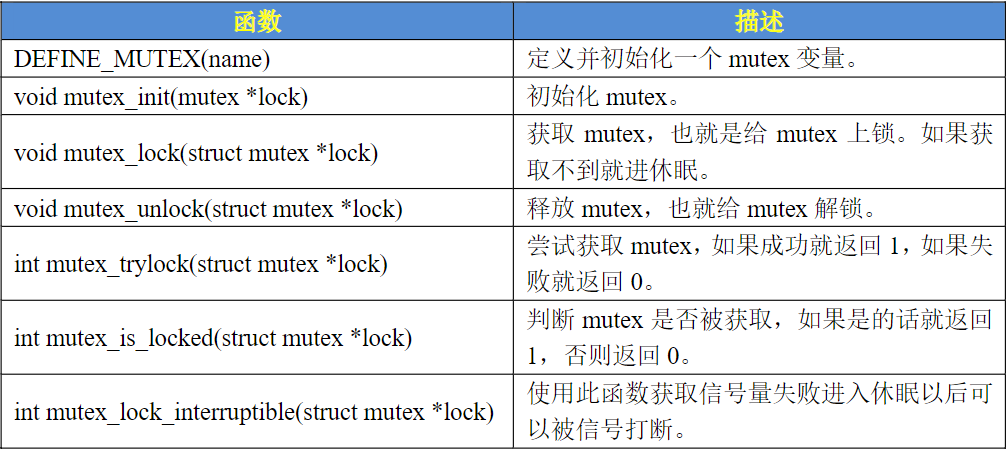
互斥体mutex
互斥访问表示一次只有一个线程可以访问共享资源,不能递归申请互斥体。
structmutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
};
因为一次只有一个线程可以持有mutex,因此,必须由mutex的持有者释放mutex。并且mutex不能递归上锁和解锁